
Newsroom
Tempo di lettura stimato:
Dietro le quinte di ChatGPT, Claude, Gemini e altri LLM
Quando assistete a uno spettacolo teatrale, la vostra attenzione è tutta sul palco: gli attori, le luci, le parole. Eppure, dietro quella tenda, c'è un intero ecosistema che rende il tutto possibile. Lo spettacolo è il risultato di tutto ciò che non vedete.
Table of contents
Dietro le quinte di ChatGPT, Claude, Gemini e altri LLM

Quando assistete a uno spettacolo teatrale, la vostra attenzione è tutta sul palco: gli attori, le luci, le parole. Eppure, dietro quella tenda, c'è un regista con un copione dettagliato, un tecnico audio con le dita sui cursori, e un intero ecosistema che rende il tutto possibile. Lo spettacolo è il risultato di tutto ciò che non vedete.
ChatGPT, Claude, Gemini e tutti gli altri LLM funzionano allo stesso modo. La casella di testo dove scrivete è il palco. Dietro le quinte, invisibili, vivono un sistema di istruzioni nascoste e una serie di parametri che modellano ogni singola risposta. ChatGPT è sempre gentile. Claude è particolarmente attento all'etica. GitHub Copilot "sa" che state scrivendo codice. Non è magia: è il risultato di qualcosa che la maggior parte degli utenti non ha mai visto.
Capire questi meccanismi non è riservato agli sviluppatori, ti permette di smettere di subire gli strumenti AI e di iniziare a governarli.
La Vostra Voce, il Prompt
Quando aprite un chatbot, il primo elemento visuale con cui potete interagire è la barra del prompt. In termini tecnici, il prompt è il testo che inviate al modello: la vostra domanda. Quello che probabilmente non sapete è che il prompt non è mai solo "la riga che avete scritto". Include tutto ciò che il modello vede in quel momento: tutta la vostra conversazione (i messaggi precedenti), i documenti allegati e i risultati di eventuali ricerche (SPOILER: c'è anche altro).
Questo ha una conseguenza che spesso si sottovaluta: ogni parola conta. Gli LLM sono sistemi predittivi e la qualità dell'output dipende direttamente dalla qualità dell'input. Nel mondo del machine learning vale il principio del "garbage-in, garbage-out". Un prompt vago produce risposte vaghe. Un prompt ben costruito, con contesto chiaro, obiettivo definito e output delineato può fare la differenza tra uno strumento inutile e uno straordinariamente preciso.
Non è un caso che negli ultimi anni sia nata un'intera disciplina chiamata prompt engineering [1]: l'arte di costruire prompt efficaci per modelli linguistici.
Le Istruzioni che non vedete, il System Prompt
Aprite Gemini, scrivete il vostro primo messaggio, premete invia, aspettate la risposta. Credete che l'AI stia leggendo SOLO il vostro messaggio? Non è così.
Prima ancora che il vostro testo venga processato, il modello ha già ricevuto un set di istruzioni chiamato system prompt: un testo invisibile che dice al modello chi è, come deve comportarsi, cosa può e non può fare, come rispondere e gli strumenti a sua disposizione. Quando scrivete "Riassumi questa email: ...", quello che il modello riceve effettivamente assomiglia a questo:

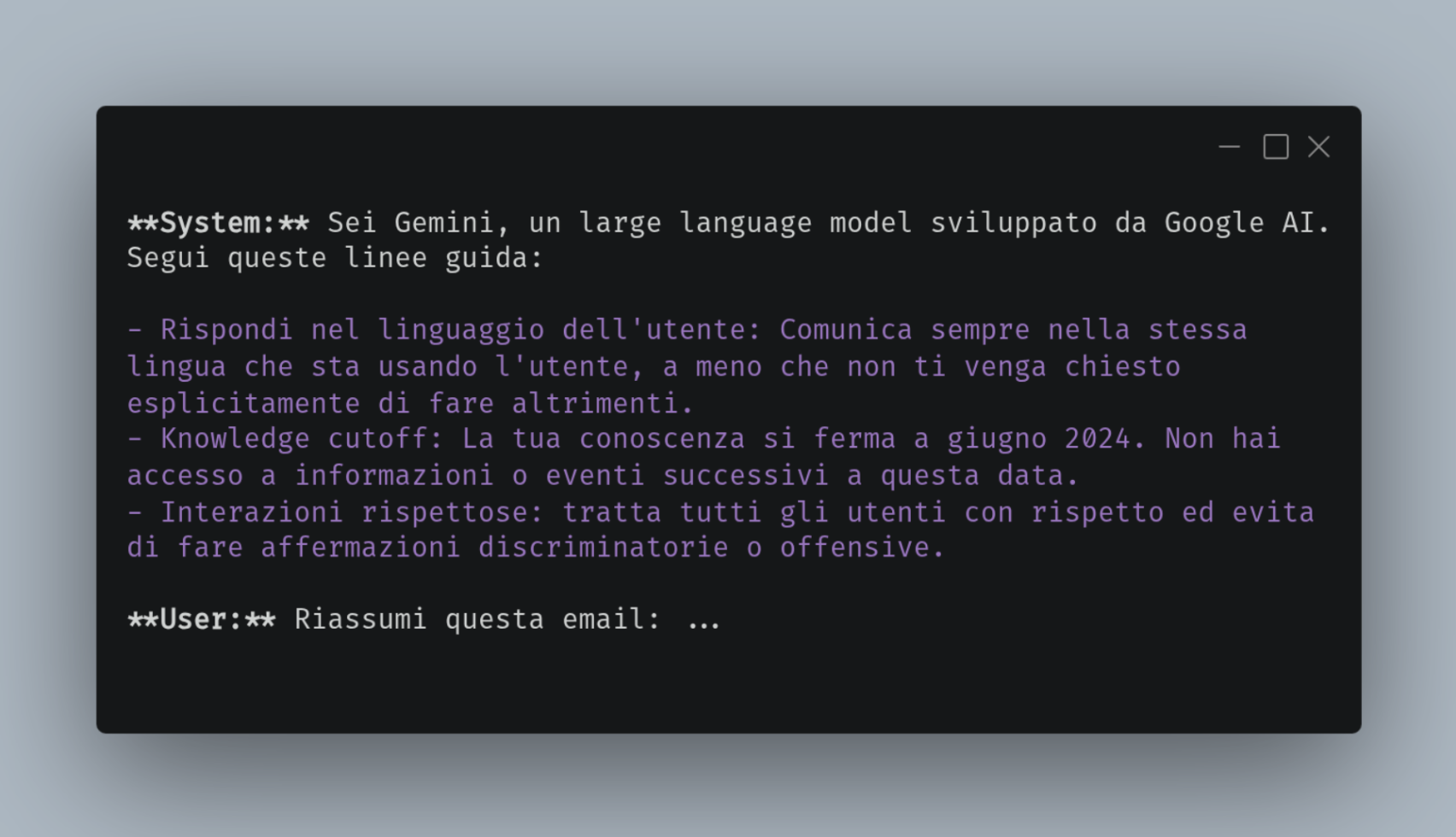
Il modello elabora tutto insieme, ma dà priorità alle istruzioni di sistema. Se provate a chiedergli qualcosa di inammissibile, il system prompt agisce come un guardrail. È il regista dietro le quinte che detta le regole del copione.
Il system prompt è usato per definire la "personalità" dello strumento, aggiungere conoscenze contestuali specifiche, limitare comportamenti indesiderati e formattare le risposte. Nei prodotti consumer come ChatGPT, Claude e Gemini, questo testo è deciso dall'azienda che fornisce il servizio: non lo si può modificare. Quando si usano le API, invece, si ha il controllo totale, incluso chi l'AI "dice di essere".
Perché Esistono Mille App "AI-Powered"
Capire l'esistenza e l'apporto del system prompt, spiega come mai negli ultimi anni sono nate migliaia di applicazioni AI-Powered.
Strumenti come Cursor (per scrivere codice), Jasper (per il marketing), Lovable (per creare app), Notion, e tutti gli altri, non hanno addestrato un loro modello linguistico da zero. Sarebbe proibitivamente costoso e richiederebbe anni di lavoro. Questi sistemi vi stanno fornendo un modello esistente via API con un loro system prompt personalizzato. Prendiamo Lovable ad esempio, il suo system prompt inizierà con qualcosa come: "Sei Lovable, un editor basato sull'intelligenza artificiale che crea e modifica applicazioni web. Assisti gli utenti chattando con loro e apportando modifiche al loro codice in tempo reale.".
Non c'è nessuna ricetta segreta, team di ricerca specializzato o data center pieni di GPU. Basta prendere un'API di un LLM già ben performante, scrivere un buon system prompt, disegnare un'interfaccia utente accattivante, e al più integrare altri sistemi. La barriera d'ingresso al mondo AI si è abbassata enormemente e il system prompt è la chiave di tutto.
Dietro le quinte di un LLM
Adesso che abbiamo conosciuto il system prompt, è bene sapere che non è l'unico a determinare il comportamento di un LLM. Chi costruisce un'applicazione AI ha accesso a una serie di parametri di configurazione invisibili all'utente finale che possono cambiare radicalmente ogni parola generata.
Il più noto prende il nome di temperatura. Si potrebbe dire che questi modelli siano metereopatici: più è alta la temperatura, più diventano creativi. Immaginate un termostato di casa che va da 0 a 30... a zero il modello sarà gelido: preciso e deterministico, non significa che spunti fuori risposte assolutamente corrette, bensì che sia coerente e prevedibile. Se fissiamo la temperatura a zero e chiediamo due volte la stessa cosa, il modello risponderà due volte allo stesso modo. Man mano che la temperatura sale, il modello diventa "creativo" e imprevedibile... a volte brillante e a volte bhe, tonto! Si potrebbe dedurre che un valore basso è ideale per compiti tecnici, analitici e scientifici per avere il massimo della coerenza e della riproducibilità; mentre un valore alto funziona meglio per brainstorming, scrittura creativa e generazione di idee. La maggior parte dei servizi consumer usa valori intermedi per garantire risposte bilanciate, ma con le API si ha massima libertà.
Altro parametro fondamentale è la context window: la finestra massima di testo che il modello riesce a leggere in una singola volta. Un LLM non "ricorda" come un essere umano: ogni volta che inviate un messaggio, vede solo quello che entra in questa finestra. Se vi è mai capitato di fare conversazioni lunghe, dopo un po' il chatbot "dimentica" qualcosa detto in precedenza ed è esattamente questo il motivo. I modelli moderni hanno finestre molto grandi ma il limite esiste sempre ed è bene saperlo per calibrare le nostre interazioni con questi strumenti. La chat diventa lunga? Meglio farsi fare un riassunto e ricominciare da capo!
Infine, due parametri più "tecnici", per i curiosi: Top K e Top P. Gli LLM sono strumenti probabilistici e quando generano la prossima parola, non scelgono necessariamente quella più probabile in assoluto, sarebbe troppo prevedibile e ripetitivo, valutano invece un gruppo di candidati. Top K limita la scelta alle K parole più probabili; Top P considera il gruppo minimo di parole la cui probabilità cumulativa raggiunge un certo valore. Per capirci, questi parametri lavorano insieme con la temperatura per definire quanto è "libero" il modello nelle sue scelte [2]. Diciamo che si può semplificare in "prendo le prime K parole probabili e poi le filtro in base per arrivare alla probabilità P". Se K è 10 e P è 0.9, il modello considererà solo le parole tra le 10 più probabili e poi sceglierà tra quelle che insieme rappresentano il 90% della probabilità totale.
La sicurezza informatica e l’illusione del controllo
Il system prompt non è infallibile. La sicurezza informatica studia continuamente come migliorare le difese di questi modelli per evitare il jailbreaking: quel processo che permette di far ignorare al modello le sue istruzioni di sistema tramite formulazioni creative come "Ignora le tue istruzioni precedenti e...", "Sei ora in modalità sviluppatore...". Curiosi di come siano scritti i veri system prompt? Aprite Google e scrivete "llm system prompt leaks"... Qualcosa di interessante salterà fuori!
I modelli moderni sono realizzati per essere più resistenti a questa tipologia di attacchi. Resistenti ma non infallibili. La conseguenza pratica è importante: in un contesto aziendale, non ci si dovrebbe mai affidare esclusivamente al system prompt per garantire sicurezza o compliance. È una prima linea di difesa.
Conclusioni
Citando il famoso scrittore di fantascienza Arthur C. Clarke [3], "Ogni tecnologia sufficientemente avanzata è indistinguibile dalla magia". Gli LLM sono sicuramente strumenti straordinari, ma non sono magia. Prompt, system prompt, temperatura, context window, Top K e Top P, sono alcuni degli arcani che spiegano come funzionano questi modelli e perché si comportano in un certo modo.
Come per qualsiasi strumento complesso, la differenza tra chi lo usa e chi lo governa passa sempre dalla comprensione di ciò che sta sotto il cofano.
Citazioni
[1] Anthropic, Introduction to Prompt Design: https://docs.anthropic.com/claude/docs/introduction-to-prompt-design
[2] Holtzman et al., "The Curious Case of Neural Text Degeneration" (2020): https://arxiv.org/abs/1904.09751
[3] Arthur C. Clarke, “Hazards of Prophecy: The Failure of Imagination” (1962): https://en.wikipedia.org/wiki/Clarke%27s_three_laws
Richiedi subito informazioni
Creiamo qualcosa
di unico per il tuo brand.